Domina los datos

Las empresas están absolutamente llenas de datos. Desde información demográfica hasta laboral, de los softweares que utiliza, de las redes sociales en las que sale… todos esos datos se encuentran en decenas o cientos de fuentes distintas.
De esta manera, tendremos un lugar único y homogéneo en el que consultar la información y seremos capaces de tomar decisiones de negocio de forma más ágil y certera, gracias al cruce de datos de distintas fuentes y a la simplicidad en la representación de los mismos.
La importancia de unificar las fuentes de datos
El aprovechamiento de los datos es algo valiosísimo para mejorar los resultados de las empresas y alcanzar sus objetivos pero, para ello, lo primero es organizar el caos que generalmente produce la multiplicidad y variedad de fuentes de información.
Si queremos aprovechar la potencia de los datos, es fundamental que unifiquemos para así poder explotarlos de la forma correcta.
El objetivo: convertir los datos en información y, a partir de la información, ser capaces de extraer conocimiento valioso para la toma de decisiones; todo esto mediante el uso de las tecnologías y las metodologías de Business Intelligence.
El Data warehouse: todos tus datos en un solo lugar
Generalmente, la información en las empresas se encuentra en herramientas de trabajo como un CRM, ERP, softwares de contabilidad, de gestión o, incluso, en Excel. Todos ellos están perfectamente diseñados para insertar datos, pero no están creados para servir información en tiempo real, por ejemplo.
Sus bases de datos son óptimas para la inserción de datos, pero no para la extracción. Por esa razón, uno de los primeros trabajos que se debe hacer cuando una empresa decide dar el salto y explotar sus datos al máximo es localizar todas esas fuentes de información y extraer los datos para volcarlos en una base de datos adecuada para su transformación, extracción y visualización. Ese tipo de bases de datos es lo que se conoce como Data Warehouse.
El proyecto BI: diferencias entre Data WareHouse, Data Lake y Data Mart
El mayor desafío de todos los proyectos de BI es la calidad de los datos de origen, su localización, extracción y normalización.
Este es un esquema simple de un proyecto tipo de BI:
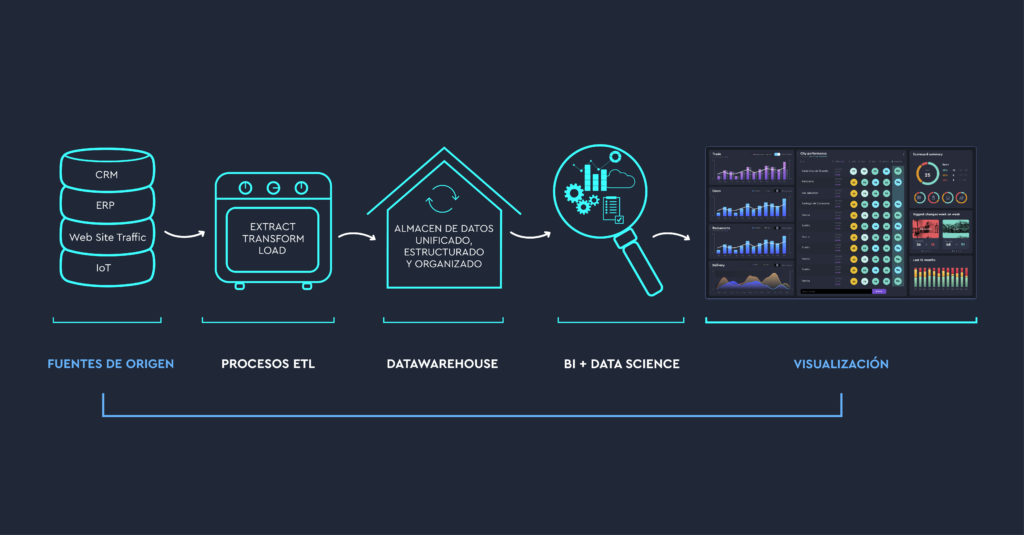
Tradicionalmente, el procedimiento para la explotación pasa por insertar los datos sin procesar, «en crudo», en una base de datos, que se conoce como Data Lake. Los data lake no están organizados, ni estructurados, simplemente son, como su nombre indica, un lago de datos.
En ese lago es en el que “se pesca” la información para tratarla y organizarla en un Datawarehouse. Los datos que hay en el datawarehouse se han trabajado previamente a través de unos procesos de programación que se conocen como ETL.
Una vez los datos están transformados y organizados se cargan en otra base de datos, o varias, mucho más pequeñas que el datawarehouse, y que se conoce como Data Mart. Lo habitual es que cada Data Mart contenga los datos de un área concreta de la empresa: Finanzas, ventas, marketing…
¿Qué es ETL?
Sus siglas en español significan Extracción, transformación y carga. Se trata de líneas de código de programación que sirven para que los datos que hemos extraído de diferentes fuentes y que pueden tener formatos distintos se pueden combinar, para trabajar con ellas de forma conjunta. Los trabajos ETL se pueden escribir en múltiples lenguajes de programación, como Java, Python, SQL…
¿Es necesario contar con estos tres tipos de bases de datos?
No. Dependerá del proyecto de BI que se necesite llevar a cabo, del punto en el que se encuentra la empresa, del volumen de datos, de la velocidad de carga que se precise, de la inmediatez que se requiera a los datos…
Procesamiento ETL
Para tomar esta decisión lo más importante es contar con la ayuda de un profesional que conozca todas las posibilidades. Hoy en día la tecnología Big Data es muy extensa y es fundamental saber qué herramientas utilizar. Por no adentrarnos en detalles demasiado técnicos resumimos lo fundamental en este apartado.
Lo primero que debes saber es que el proyecto de BI que lleves a cabo puede funcionar en un hosting tradicional (contratación de servidores físicos para alojar en ellos el proyecto) o en Cloud, cuya principal característica es que la información se replica entre diferentes nodos de red y no en un único servidor físico.
Las ventajas del Cloud
Para un proyecto de Big Data que, por su propia naturaleza, tenderá a crecer de forma constante, los servicios Cloud suelen ser los más apropiados ya que son flexibles y aumentan según la necesidad de proyecto. Para simplificarlo, funcionan como la electricidad en las casas: Contratas el servicio Cloud y en función del consumo (almacenamiento, consultas, velocidad…), pagas.
Esta característica es una de las razones por las que es fundamental contar con expertos a la hora de utilizar servicios en la nube como Amazon, Azure (Microsoft) o Google Cloud, ya que los costes se pueden disparar si no se optimizan de forma correcta los recursos.
Bien utilizado, las ventajas del Cloud son evidentes. Menor coste y más rentabilidad, mayor consistencia (si un nodo falla, la información se replica a otro de forma automática), más seguridad o disponibilidad de múltiples prestaciones en cada una de las plataformas disponibles.
¿Qué tipo de base de datos utilizo?
Otro punto importante sobre la tecnología en los proyectos de BI es el tipo de base de datos a utilizar, o las herramientas que se utilicen para llevar a cabo las ETL.
Respecto a las bases de datos la diferencia más evidente es la cantidad de datos a procesar y la velocidad que se requiera para la representación de los mismos. Aquí de nuevo, contar con profesionales que conozcan y controlen todas las opciones es clave.
Las bases de datos relacionales son las que se han usado en los softwares y aplicaciones de negocio en los últimos 40 años. Pueden utilizarse para el tratamiento de Big Data, pero es muy posible que se queden cortas en prestaciones. Precisamente por la necesidad de manejar con facilidad enormes cantidades de datos surgieron otro tipo de bases de datos que no utilizan tablas, campos y filas como las relacionales y que se conocen como NoSQL.
Solo por nombrar algunas, las bases de datos más comúnmente utilizadas para proyectos de BI son: Oracle, MongoDB, Redfshit de Amazon o Kassandra entre otras.


